Laboratory Works
Laboratory work Nr. 3
Kruskal Algorithm
Kruskal’s algorithm is a minimum-spanning-tree algorithm which finds an edge of the least possible weight that connects any two trees in the forest. It is a greedy algorithm in graph theory as it finds a minimum spanning tree for a connected weighted graph adding increasing cost arcs at each step. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. If the graph is not connected, then it finds a minimum spanning forest (a minimum spanning tree for each connected component).
The same principle is represented in the following image:

Next, follows the code implementation:
vertices=5
matrix=[[1000,1,3,4,1000],[1,1000,5,1000,7],[3,5,1000,6,8],[4,1000,6,1000,2],[1000,7,8,2,1000]]
row=[0]
for i in range(vertices-1):
row_num,col_num,min_no = -1,-1,1000
for i in row:
print "this is row", row
temp = min(matrix[row[i]])
if(min_no > temp):
min_no = temp
row_num = i
col_num = matrix[i].index(temp)
print str(min_no)+"("+str(row_num)+","+str(col_num)+")"
for i in range(vertices):
matrix[i][col_num] = 1000
row.append(col_num)
d = raw_input()

Conlusion:
Kruskal’s algorithm is pretty simple. Intuitively, it collects the cheapest eligible edges which bolsters the belief that the “minimum” part in the caption (Minimum Spanning Tree) may well be justified. The algorithm avoids loops maintaining at every stage a forest of a finite number of trees. The number of trees can’t grow indefinitely so that one may expect that, with time, some trees will be bridged into a single tree until only one tree remains.
Floyd Algorithm
The Floyd–Warshall algorithm is an algorithm for finding shortest paths in a weighted graph with positive or negative edge weights (but with no negative cycles). A single execution of the algorithm will find the lengths (summed weights) of the shortest paths between all pairs of vertices, though it does not return details of the paths themselves.
Python code of the program:
import math
def printSolution(distGraph):
string = "inf"
nodes =distGraph.keys()
for n in nodes:
print "\t%6s"%(n),
print " "
for i in nodes:
print"%s"%(i),
for j in nodes:
if distGraph[i][j] == INF:
print "%10s"%(string),
else:
print "%10s"%(distGraph[i][j]),
print" "
def floydWarshall(graph):
nodes = graph.keys()
distance = {}
for n in nodes:
distance[n] = {}
for k in nodes:
distance[n][k] = graph[n][k]
for k in nodes:
for i in nodes:
for j in nodes:
if distance[i][k] + distance[k][j] < distance[i][j]:
distance[i][j] = distance[i][k]+distance[k][j]
printSolution(distance)
INF = 999999999
if __name__ == '__main__':
graph = {'A':{'A':0,'B':6,'C':INF,'D':6,'E':7},
'B':{'A':INF,'B':0,'C':5,'D':INF,'E':INF},
'C':{'A':INF,'B':INF,'C':0,'D':9,'E':3},
'D':{'A':INF,'B':INF,'C':9,'D':0,'E':7},
'E':{'A':INF,'B':4,'C':INF,'D':INF,'E':0}
}
floydWarshall(graph)
Conclusion:
A shortest path problem can be easily solved by using the Floyd Algorithm. It is not very complicated, talking prom implementable point of view, but is very efficient. The above program only prints the shortest distances. We can modify the solution to print the shortest paths also by storing the predecessor information in a separate 2D matrix. Also, the value of INF can be taken as INT_MAX from limits.h to make sure that we handle maximum possible value. When we take INF as INT_MAX, we need to change the if condition in the above program to avoid arithmatic overflow.
Laboratory work Nr. 2
Merge Sort Method
def mergeSort(_list):
print("Splitting ",_list)
if len(_list)>=2:
mid = len(_list)//2
firstHalf = _list[:mid]
secondHalf = _list[mid:]
mergeSort(firstHalf)
mergeSort(secondHalf)
i=0
j=0
index=0
while i < len(firstHalf) and j < len(secondHalf):
if firstHalf[i] < secondHalf[j]:
_list[index]=firstHalf[i]
i=i+1
else:
_list[index]=secondHalf[j]
j=j+1
index+=1
while i < len(firstHalf):
_list[index]=firstHalf[i]
i=i+1
index+=1
while j < len(secondHalf):
_list[index]=secondHalf[j]
j=j+1
index+=1
print("Merging ",_list)
list = [32,211,93,14,56,32,29,43,20]
mergeSort(list)
print(list)
Results:
Splitting [32, 211, 93, 14, 56, 32, 29, 43, 20]
Splitting [32, 211, 93, 14]
Splitting [32, 211]
Splitting [32]
Merging [32]
Splitting [211]
Merging [211]
Merging [32, 211]
Splitting [93, 14]
Splitting [93]
Merging [93]
Splitting [14]
Merging [14]
Merging [14, 93]
Merging [14, 32, 93, 211]
Splitting [56, 32, 29, 43, 20]
Splitting [56, 32]
Splitting [56]
Merging [56]
Splitting [32]
Merging [32]
Merging [32, 56]
Splitting [29, 43, 20]
Splitting [29]
Merging [29]
Splitting [43, 20]
Splitting [43]
Merging [43]
Splitting [20]
Merging [20]
Merging [20, 43]
Merging [20, 29, 43]
Merging [20, 29, 32, 43, 56]
Merging [14, 20, 29, 32, 32, 43, 56, 93, 211]
[14, 20, 29, 32, 32, 43, 56, 93, 211]
Quick Sort Method
def quickSort(_list):
quickSortHelper(_list,0,len(_list)-1)
def quickSortHelper(_list,first,last):
if first<last:
splitpoint = partition(_list,first,last)
quickSortHelper(_list,first,splitpoint-1)
quickSortHelper(_list,splitpoint+1,last)
def partition(_list,first,last):
pivotvalue = _list[first]
leftmark = first+1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and _list[leftmark] <= pivotvalue:
leftmark = leftmark + 1
while _list[rightmark] >= pivotvalue and rightmark >= leftmark:
rightmark = rightmark -1
if rightmark < leftmark:
done = True
else:
temp = _list[leftmark]
_list[leftmark] = _list[rightmark]
_list[rightmark] = temp
temp = _list[first]
_list[first] = _list[rightmark]
_list[rightmark] = temp
return rightmark
list = [32,211,93,14,56,32,29,43,20]
quickSort(list)
print(list)
Results:
[14, 20, 29, 32, 32, 43, 56, 93, 211]
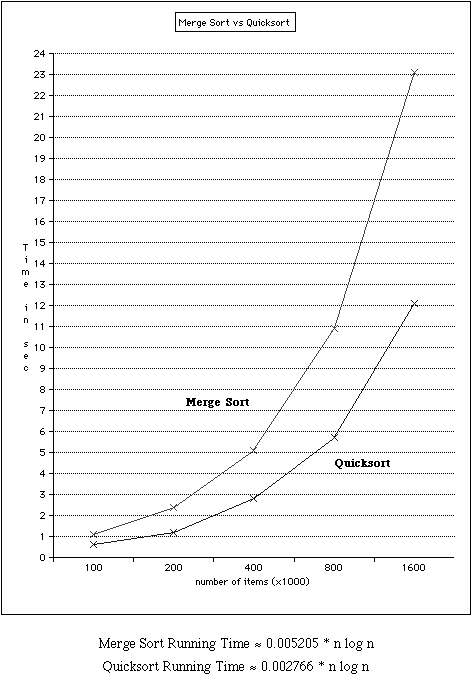
Conclusion:
By performing this laboratory work we learned how to work with mergesort and quicksort algorithms. What can be said is that while quicksort is often a better choice than merge sort, there are definitely times when merge sort is thereotically a better choice. The most obvious time is when it’s extremely important that your algorithm run faster than O(n2). Quicksort is usually faster than this, but given the theoretical worst possible input, it could run in O(n2), which is worse than the worst possible merge sort.
Quicksort is also more complicated than mergesort, especially if you want to write a really solid implementation, and so if you’re aiming for simplicity and maintainability, merge sort becomes a promising alternative with very little performance loss.
Laboratory work Nr. 1
Ex.1
from math import *
from time import time
import matplotlib.pyplot as plt
#here is the firs(recursion) method
n = 10
n2 = 10
def fibonacci_rec(n):
if n < 2:
return n
else:
return fibonacci_rec(n-1) + fibonacci_rec(n-2)
def f1(n):
startTime = time()
fibonacci_rec(n)
return time() - startTime
#here is the second mehtod(using loop)
def fibonacci_for(n):
i = 1
j = 0
for k in range(n):
j = i + j
i = j - i
return j
def f2(n2):
startTime = time()
fibonacci_for(n2)
return time() - startTime
#here is the code in function 3
def fibonacci_third(n):
i = 1
j = 0
k = 0
h = 1
while (n > 0):
if n % 2 != 0:
t = j * h
j = i * h + j * k + t
i = i * k + t
t = h * h
h = 2 * k * h + t
k = k * k + t
n = n / 2
return j
def f3(n2):
startTime = time()
fibonacci_third(n2)
return time() - startTime
def timeMeasure(func):
startTime = time()
a = func
return time() - startTime
A = []
C = []
B = []
for i in range(15):
A.append(f1(i))
B.append(f2(i))
C.append(f3(i))
plt.plot(A)
plt.plot(C)
plt.plot(B)
plt.show()

Conclusion
By analyzing the results it can be reasonably said that the algorithms don’t have the same complexity. The thing is, in a given interval of time, the algorithms converge in a different way.
When doing the recursive implementation of fibonacci algorithm, you are adding redundant calls by recomputing the same values over and over again.
Iterative functions – are loop based imperative repetitions of a process (in contrast to recursion which has a more declarative approach).
This is the main difference between these approaches.
P.S. There are lots of algorithms for computing fibonacci that can be found on google.